Advancing Extreme Multi-Label Text Classification for Less-Represented Languages
Dr Nada Lavrač has published a new research article titled “Extreme Multi-Label Text Classification for Less-Represented Languages and Low-Resource Environments: Advances and Lessons Learned” with co-authors. The study addresses a major challenge in contemporary Natural Language Processing (NLP): developing efficient, scalable, and robust text classification systems for multilingual and low-resource contexts.
Small Language Models
In recent years, there has been rapid progress in extremely large, multimodal large language models. At the same time, interest is growing in efficient Small Language Models (SLMs) that can operate without relying on large data centre infrastructure. However, despite their potential, most existing SLMs are primarily trained on high-resource languages such as English. This significantly limits their applicability in industries that require reliable NLP solutions for less-represented languages, low-latency processing, and adaptability to rapidly evolving label spaces. These limitations are especially pronounced in media monitoring, where systems must process very large volumes of content in near real time, under strict latency and cost constraints, and often in multiple languages.
Extreme Multi-Label Classification in Media Monitoring
The newly published paper examines a retrieval-based approach to multi-label text classification (MLC) for a media monitoring dataset, with particular emphasis on less-represented languages such as Slovene. The research task constitutes an extreme multi-label classification (XMC) challenge, as individual texts may be annotated with up to twelve thousand distinct categories.
The study is based on NewsMon, a large-scale dataset constructed from a Slovenian media monitoring industry archive. The original dataset contains over one million data points and more than ten thousand client-defined “topics”, which serve as labels in a multi-label classification task. The overall news monitoring archive contains over 85 million articles marked with more than 96,000 arbitrary “client topics”. The sampled NewsMon dataset comprises one million articles from eight countries (Serbia, Slovenia, Bosnia and Herzegovina, Croatia, North Macedonia, Montenegro, Kosovo, and Albania) in nine languages.
A Retrieval-Based, Model-Agnostic Approach
To address these challenges, the paper proposes a retrieval-based approach to XMC, building on the Retrieval-Augmented Encoders for XMC (RAE-XMC) framework. The method uses a single-encoder architecture to embed both documents and labels, and prioritises computational efficiency, multilingual robustness, and adaptability to frequent label changes. Importantly, the approach is model-agnostic, as it does not rely on a specific model architecture or language-specific training data. This makes it particularly well suited for deployment in low-resource environments and on consumer-grade hardware.
Research Questions
The study investigates four research questions:
RQ1 Can we overcome the traditional one-versus-all (OVA) Transformer Encoder (TE) classification baselines in a multilingual setting?
RQ2 How effective is the method without label description embeddings?
RQ3 Can pre-trained multilingual IR models be used effectively without fine-tuning?
RQ4 Can we improve the method by incorporating additional contrastive learning with hard negative mining?
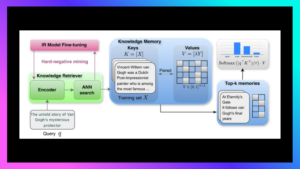
Key Findings and Contributions
The results demonstrate several important advances:
- Information retrieval (IR) models can outperform end-to-end fine-tuned Transformer models when dealing with extremely large label spaces, offering a computationally efficient alternative.
- A significant performance gap remains between end-to-end models and IR-based approaches in less-represented, non-English languages, making IR models particularly suitable for multilingual XMC tasks.
- Incorporating contrastive learning with precomputed hard negatives improves performance when applying the method to new, multilingual datasets.
- The approach remains effective without relying on label embeddings and can handle longer texts than those typically considered in XMC research.
- The method adapts well across languages, with no significant performance degradation in Slovene, demonstrating its suitability for multilingual deployment.
Practical Impact and Novelty
The main innovation of this work is the use of an information retrieval-based classification framework for multilingual, extreme multi-label settings, specifically addressing low-resource languages and dynamic label spaces. Unlike conventional end-to-end models, the proposed approach performs competitively even without continuous fine-tuning, making it highly adaptable to real-world media monitoring scenarios.
On the NewsMon dataset, the method outperforms the XLM-R baseline across all evaluation metrics, while maintaining the low latency, scalability, and robustness required for production systems.
Advancing Multilingual NLP in Practice
By demonstrating that retrieval-based XMC can outperform large, fine-tuned models under realistic operational constraints, this publication contributes valuable insights for both research and industry. It highlights a viable path forward for building cost-efficient, multilingual NLP systems that serve less-represented languages without sacrificing performance or scalability.
The article is available on this link.